Python #4 (struktury danych)

PRZYDATNE: Zakomentowanie/Odkomentowanie w VS Code - Ctrl + /
W Pythonie struktury danych są potrzebne, ponieważ pozwalają nam efektywnie przechowywać, organizować i przetwarzać informacje.
- Organizacja danych - struktury danych (np. listy, krotki, słowniki, zbiory) pomagają logicznie uporządkować informacje. Dzięki temu program jest bardziej czytelny i łatwiej nim zarządzać.
- Efektywność - każda struktura danych ma swoje zalety wydajnościowe. Dzięki temu programy mogą działać szybciej i zużywać mniej pamięci. Na przykład:
- Wyszukiwanie elementu w słowniku jest bardzo szybkie;
- Usuwanie duplikatów łatwo zrobić używając zbioru.
- Elastyczność i łatwość rozbudowy - struktury danych to podstawowe klocki, na których można budować własne rozwiązania.
Podstawowe struktury danych wbudowane
Lista (list)
- Dynamiczna tablica przechowująca elementy w określonej kolejności.
- Może zawierać różne typy danych.
- Przykład listy : liczby = [1, 2, 3]
mojeksiazki = ["Blade Runner", "Fundacja", "Władca Pierścieni", "Forest Gump", "Kłamca", "Amerykańscy Bogowie"]
# Sprawdź co jest pod indeksem 4
print(mojeksiazki[4])# # fajnie gdy nie mieszamy typów na liście
mojalista = ["nagolenniki" , "zbroja" , "hełm" , "miecz"]
kiepska_lista = ["Nagolenniki" , 3.14 , 6 , "kot"]
# Dodawanie obiektu do listy
mojalista.append("sztylet")
print(mojalista)
## Wynik:['nagolenniki', 'zbroja', 'hełm', 'miecz', 'sztylet']
# Dodawanie obiektu inaczej (też na końcu jak append)
mojalista = ["a", "b", "c", "d", "e"]
mojalista += ["white"]
print(mojalista) # ['a', 'b', 'c', 'd', 'e', 'white']
# Usuwanie obiektu z listy
mojalista.remove("nagolenniki")
print(mojalista)
## Wynik: ['zbroja', 'hełm', 'miecz', 'sztylet']
# Alternatywne do .remove usuwanie obiektu o danym indeksie
lista = ['a', 'b', 'c', 'd', 'b']
del lista[1] # ['a', 'd', 'b']
# Usuwanie ostatniego obiektu na liście (lub obiektu o określonym indeksie)
mojalista.pop()
print(mojalista)
## Wynik: ['zbroja', 'hełm', 'miecz']
# Rozszerza listę o elementy z innej kolekcji (np. innej listy).
mojalista.extend(["Różdżka" , "Mikstura"])
print(mojalista)
## Wynik: ['zbroja', 'hełm', 'miecz', 'Różdżka', 'Mikstura']
# insert(i, x) Wstawia element x na pozycję i.
mojalista.insert(0 , "Nagolenniki")
print(mojalista)
## Wynik: ['Nagolenniki', 'zbroja', 'hełm', 'miecz', 'Różdżka', 'Mikstura']
# index(x) Zwraca indeks pierwszego wystąpienia elementu x.
print(mojalista.index("hełm"))
## Wynik: 2
# count(x) Liczy, ile razy element x występuje w liście.
print(mojalista.count("hełm"))
## Wynik: 1
# Wyszukiwanie i sprawdzanie w liście
owoce = ["jabłko", "banan", "pomarańcza", "banan"]
# Sprawdź czy element jest w liście
print("banan" in owoce) #True
print("gruszka" in owoce) #False
print("gruszka" not in owoce and "banan" in owoce) #True
# Znajdź pozycję elementu
print(owoce.index("pomarańcza")) #2
# lub
pozycja = owoce.index("pomarańcza") #2
print(pozycja)
# Policz ile razy element występuje
print(owoce.count("banan")) #2
# Długość listy len to Funkcja!
print(len(owoce)) #4
# Łączenie list (+)
lista1 = [1, 2]
lista2 = [3, 4]
lista3 = lista1 + lista2 # [1, 2, 3, 4]
# Dodaj do lista1 [10, 11, 12]
lista1.extend([10, 11, 12]) #[1, 2, 3, 10, 11, 12]
# Sortowanie listy:
# ascending
liczby1 = [12, 45, 7, 23, 89, 56, 34, 78, 15, 67, 3]
liczby1.sort()
print(liczby1) #[3, 7, 12, 15, 23, 34, 45, 56, 67, 78, 89]
# descending
liczby1.sort(reverse=True)
print(liczby1) #[89, 78, 67, 56, 45, 34, 23, 15, 12, 7, 3]
# alfabetycznie
imiona = ["Anna", "Bartosz", "Damian", "Celina", "Ewa", "Filip"]
print(sorted(imiona)) # ['Anna', 'Bartosz', 'Celina', 'Damian', 'Ewa', 'Filip']
print(sorted(imiona, reverse = True)) # ['Filip', 'Ewa', 'Damian', 'Celina', 'Bartosz', 'Anna']- Metody są „wbudowane” w dany typ danych i pozwalają wykonywać na nim typowe operacje. Np. dla list mamy zestaw metod do dodawania, usuwania, sortowania czy wyszukiwania elementów.
obiekt. metoda()
- Indeksowanie - Chcąc “wyciągnąć” konkretny element będący częścią listy lub krotki wpisujemy identyfikator w nawiasach kwadratowych po nazwie zmiennej .
nazwa_zmiennej[indeks]
mojalista = ["nagolenniki" , "zbroja" , "hełm" , "miecz"]
print(mojalista [1])
# Wynik: "zbroja"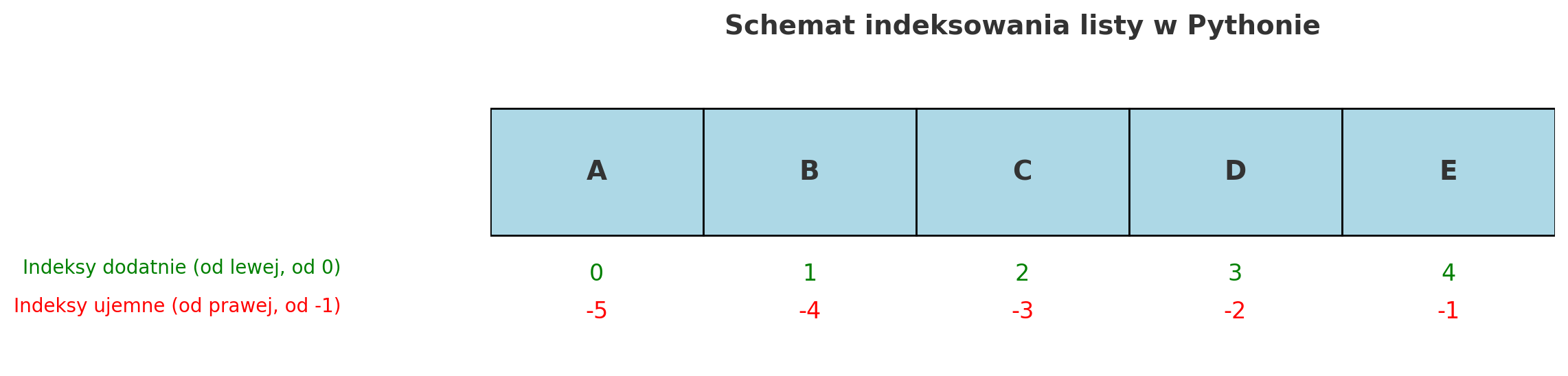
- Wycinki list (slicing)
Składnia: print(lista[start:stop:step])
start - od którego indeksu zaczynamy (włącznie)
stop - na którym indeksie kończymy (ale jego nie bierzemy)
step - co który element bierzemy (domyślnie 1)
Odwrócenie kolejności obiektów listy poprzez slicing ->[::-1]
Zapamiętaj: lista. reverse() zmienia oryginalną listę, więc jeśli chcesz nową listę, użyj slicingu!
Krotka (tuple)
- Podobna do listy, ale niemodyfikowalna (immutable).
- Często używana do przechowywania stałych zestawów danych.
- Przykład krotki: zwierzęta = ("kot" , "pies" , "chomik")
- Przykłady:
# Podstawowe tworzenie
krotka = (1, 2, 3)
mieszana = ("tekst", 42, True)
# UWAGA! Jeden element wymaga przecinka
jeden = (42,) # To krotka
nie_krotka = (42) # To zwykły int!
# Krotka zagnieżdżona w liście
colors = [
("żółty", (255, 255, 0)),
("zielony", (0, 255, 0)),
("biały", (255, 255, 255)),
("czerwony", (255, 0, 0))
]- Dostęp do obiektów:
kolory = ("czerwony", "zielony", "niebieski")
print(kolory[0]) # czerwony (przez indeks)
print(kolory[-1]) # niebieski (ostatni)
print(kolory[0:2]) # ('czerwony', 'zielony') - slicing
print(kolory[::-1]) # ('niebieski', 'zielony', 'czerwony')- Tylko 2 metody (bo niezmienne!): index i count
# Metody
liczby = (1, 2, 3, 2, 4, 2)
print(liczby.count(2)) #3
print(liczby.index(3)) #2 - znajduje indeks- Operacje na krotkach:
# Operacje na krotkach
a = (1, 2, 3)
b = (4, 5, 6)
print(a + b) # (1, 2, 3, 4, 5, 6) - łączenie
print(a * 2) # (1, 2, 3, 1, 2, 3) - powtarzanie
print(2 in a) # True - sprawdzanie
print(len(a)) # 3 - długośćSłownik (dict)
- Struktura przechowująca dane w parach {"klucz":"wartość"}.
- Bardzo szybki dostęp do elementów.
- Zapisujemy w nawiasach {"klucz":"wartość"} - Klucz musi być unikalny, nie jest modyfikowalny (np. nie może być nim lista)!
# Pusty słownik
slownik = {}
# Słownik z danymi
bohaterzy = {"istari" : "Gandalf" ,
"hobbit1" : "Frodo" ,
"hobbit2" : "Sam" ,
"hobbit3" : " Meriadok",
"hobbit4" : "Peregrin" ,
"elf" : "Legolas" ,
"krasnolud" : "Gimli" ,
"człowiek1" : "Aragorn" ,
"człowiek2" : "Boromir"
}
# print(len(bohaterzy)) # 9
print(bohaterzy.get("człowiek2")) #Boromir
print(bohaterzy.get("istari")) #Gandalf
# Dodawanie
bohaterzy["elf2"] = "Elrond"
print(bohaterzy)
# Wynik: {'istari': 'Gandalf', 'hobbit1': 'Frodo', 'hobbit2': 'Sam', 'hobbit3': ' Meriadok', 'hobbit4': 'Peregrin', 'elf': 'Legolas', 'krasnolud': 'Gimli', 'człowiek1': 'Aragorn', 'człowiek2': 'Boromir', 'elf2': 'Elrond'}
# Modyfikowanie
bohaterzy["elf"] = "Galadriel"
print(bohaterzy) # Zamiast Legolas pojawi się Galadriel pod kluczem elf
# Usuwanie #1
del bohaterzy["elf"]
print(bohaterzy.get("elf")) #None
# Sprawdzanie czy klucz istnieje
if "elf" in bohaterzy:
print(True)
else:
print(False) #True
- Najważniejsze metody
Metody słowników można podzielić na kilka grup:
- modyfikacja: update, pop, popitem, clear, setdefault
- odczyt: get, keys, values, items
- tworzenie/kopiowanie: copy, fromkeys
# update - dodaje elementy z innego słownika lub z sekwencji par (klucz, wartość).
bohaterzy.update({"elf3" : "Arwen"})
print(bohaterzy)
# get - wyciąga wartość po kluczu
print(bohaterzy.get("elf"))
# keys - zwraca widok wszystkich kluczy
print(bohaterzy.keys())
# values -zwraca widok wszystkich wartości
print(bohaterzy.values())
# items - zwraca widok par (klucz , wartość)
print(bohaterzy.items())
# pop - usuwa wartość po kluczu
bohaterzy.pop("elf")
print(bohaterzy)
# popitem - usuwa i zwraca ostatnią parę (klucz, wartość)
bohaterzy.popitem()
print(bohaterzy)
# clear – usuwa wszystkie elementy
bohaterzy.clear()
print(bohaterzy)Zbiór (set)
- Kolekcja unikalnych elementów, bez gwarancji kolejności.
- Idealny do usuwania duplikatów czy szybkiego sprawdzania przynależności.
Właściwości zbioru:
- Unikalność – każdy element występuje tylko raz
- Brak porządku – elementy nie mają ustalonej kolejności (nie ma indeksowania!)
- Mutable - można dodawać i usuwać elementy
liczby1 = {1 ,3, 5, 8, 10}
liczby2 = {2, 1, 4, 12, 8, 5, 6}
## Sprawdż czy w zbiorze jest obiekt 6
print(6 in liczby2) # True
print(6 in liczby1) # False
## Suma (| lub .union()) lub .update
print(liczby1 | liczby2) # {1, 2, 3, 4, 5, 6, 8, 10, 12}, NIE ZMIENIA ORYGINALNNYCH ZBIORÓW
print(liczby1.union(liczby2)) # {1, 2, 3, 4, 5, 6, 8, 10, 12}, NIE ZMIENIA ORYGINALNNYCH ZBIORÓW
liczby1.update({99, 100}) # {1, 3, 99, 5, 100, 8, 10} MODYF. ORYGINALNY ZBIÓR
print(liczby1)
liczby1 |= liczby2
print(liczby1) # {1, 2, 3, 4, 5, 6, 8, 10, 12} MODYF. ORYGINALNY ZBIÓR
## Część wspólna (& lub .intersection())
print(liczby1 & liczby2) # {8, 1, 5}
print(liczby1.intersection(liczby2)) # {8, 1, 5}
## Różnica (- lub .difference())
print(liczby1 - liczby2) # {10, 3}
print(liczby1.difference(liczby2)) # {10, 3}
print(liczby2 - liczby1) # {2, 4, 12, 6}
## Różnica symetryczna - Można powiedzieć, że różnica symetryczna to:
„to, co odróżnia oba zbiory od siebie”, czyli bierzesz oba zbiory, wyrzucasz część wspólną i zostaje Ci to, co jest wyłącznie w jednym lub drugim, ale nie w obu jednocześnie. ^ lub .symmetricdifference
print(liczby1 ^ liczby2) #{2, 3, 4, 6, 10, 12}
print(liczby1.symmetric_difference(liczby2)) #{2, 3, 4, 6, 10, 12}
Nie modyfikują oryginału (tworzą nowy zbiór): Operatory: | , & , - , Metody: .union(), .intersection(), .difference(), .symmetric_difference()
Modyfikują oryginalny zbiór: Modyfikują oryginał (nadpisują istniejący zbiór) Operatory ze znakiem równości: |= , &= , -=, ^= Metody z _update: .update(), .intersection_update(), .difference_update(), .symmetric_difference_update()
Zmiana listy na zbiór i odwrotnie
ksiazki = ["Endymion", "Hobbit", "Fundacja", "Endymion"]
zbior_ksiazek = set(ksiazki)
ksiazki_bez_powtorzen = list(zbior_ksiazek)Ćwiczenie
# Gracz ma ekwipunek dostępny pod zmienną ekwipunek
# ekwipunek = ["tarcza", "miecz", "napój leczący"]
# Dodaj do ekwipunku "pył magiczny"
# Jeśli w ekwipunku jest zarówno "pył magiczny" jak i "napój leczący" to dodaj do ekwipunku
# "większy napój leczący" i usuń wykorzystane składniki
ekwipunek = ["tarcza", "miecz", "napój leczący"]
ekwipunek.append("pył magiczny")
if "pył magiczny" in ekwipunek and "napój leczący" in ekwipunek:
ekwipunek.remove("pył magiczny")
ekwipunek.remove("napój leczący")
ekwipunek.append("większy napój leczący")
print(ekwipunek)Pomysły na struktury danych w quizie
Zadanie:
- osobna zmienna / struktura danych do wyników użytkowników -> słownik zawierający "użytkownik": suma pkt; historia odp
- pytania bez powtórzeń -> set z id wyświetlonych pyt
- kolejność odpowiedzi losowo -> random.shuffle()
- przechowujemy odp i pkt w tym samym miejscu / tej samej strukturze -> krotki? zagnieżdżone w liście żeby odp były razem
- kolejność przechowania punktów za odp i samego wariantu odpowiedzi ma znaczenie. Warto to zaznaczyć przy wyborze struktury danych.
Pomysły:
Słownik nadrzędny (slownik_pytan), w którym są 'podsłowniki', czyli pytania (każde ma identyfikator).
Każde pytanie to też słownik składający się z:
- "pytanie": "tekst pytania"
- "odpowiedzi": lista krotek [(odpowiedź1, punkty), (odpowiedź2, punkty), (Odpowiedź3, punkty) <- wtedy odpowiedzi będą powiązane z punktami
- pytania mają identyfikator (żeby można było ocenić czy pytania o danym identyfikatorze już się pojawiły czy nie) np. "identyfikator" : 1
slownik_pytan ={
pytanie1 = {
"identyfikator": 1,
"pytanie": "Gdzie w komórce eukariotycznej znajduje się DNA?",
"odpowiedzi": [
("W jądrze komórkowym", 1),
("W błonie komórkowej", 0),
("W cytoplazmie", 0)]}
pytanie2 = {
"identyfikator": 2,
"pytanie": "Jaką strukturę przestrzenną ma cząsteczka DNA?",
"odpowiedzi": [
("Potrójna spirala", 0),
("Podwójna helisa", 1),
("Pojedynczy łańcuch, 0)]}
}- Żeby zapewnić brak duplikatów pytań proponuję set z identyfikatorami poszczególnych pytań, które były już wyświetlone w quizie (Nie wiem jak powiązać set z identyfikatorami pytań)
- Żeby odpowiedzi były w randomowej kolejności - funkcja random.shuffle() na liście krotek. miesza całe krotki razem, więc odpowiedź i punkty dalej będą razem.
- osobna zmienna / struktura danych do wyników użytkowników - tutaj też sugerowałąbym słownik, który np. zawiera "Imię użytkownika : liczba punktów", "Identyfikator pytania1" : liczba punktów, "Identyfikator pytania2" : liczba punktów itd. LUB można zrobić słownik zagnieżdżony dla porządku: {Identyfikator pytania1: liczba punktów, Identyfikator pytania2: liczba punktów}
- warto rozważyć liczenie czasu odpowiedzi na poszczególne pytania.



