Python_Notatki Z8

Piszemy książkę kontaktową, korzystając z plików .json i td.

Tryb do odczytu - "r"

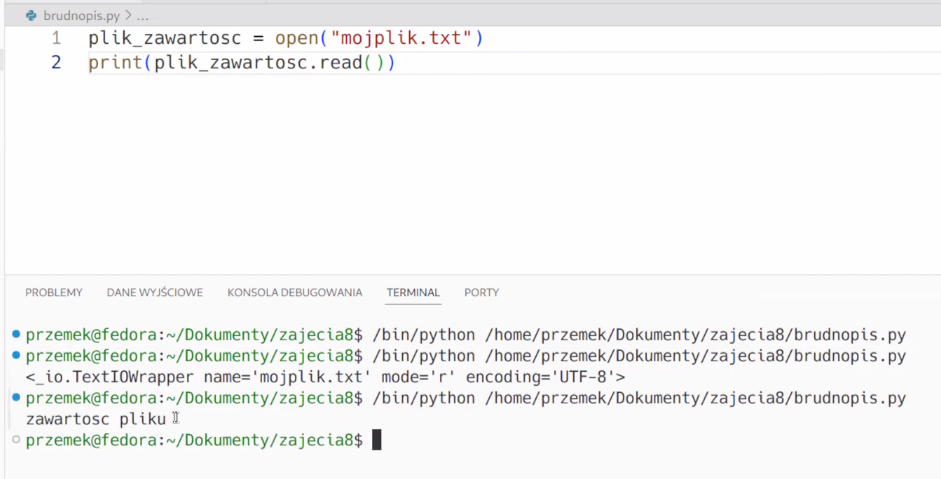
Aby odczytać zawartość, trzeba użyć wbudowanej metody .read()
Można użyć pętli dla przejścia linijka po linijce w dok tekstowym
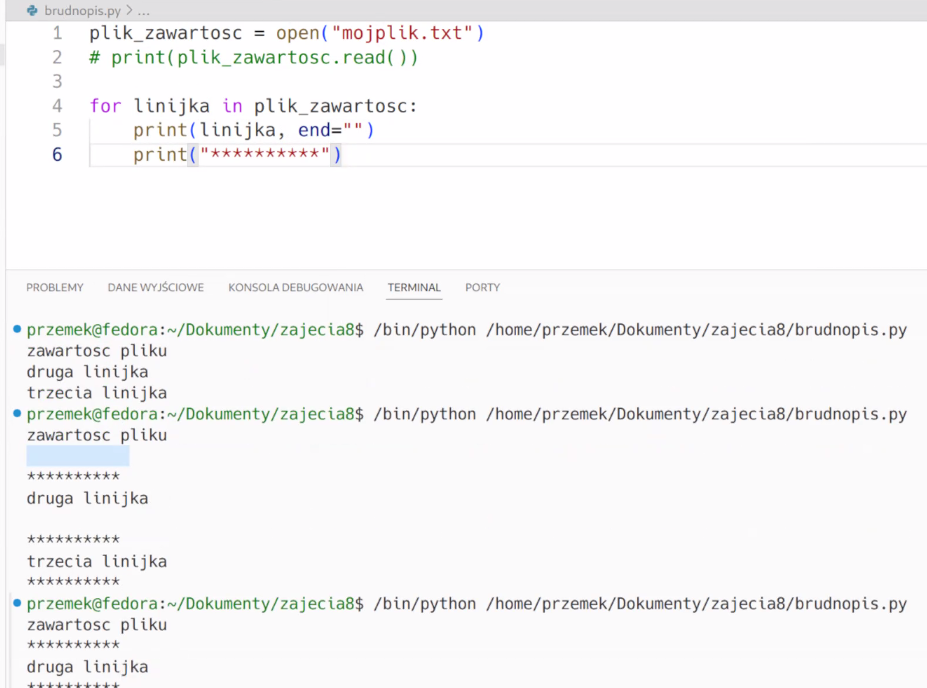
Przejście do kolejnej linijki jest też znakiem, nie tylko spacja, więc pojawiają się puste linijki przy wydruku w pętli.
Otwieranie plików:
plik_zawartosc = open("mojplik.txt")
# print(plik_zawartosc.read())
for linijka in plik_zawartosc:
print(linijka, end="")
print("***")
"w" - tryb do zapisu. W tym trybie znacznik jest na początku pliku i nadpisuję wszystko, co tam było, zamieniając na nową zawartość.
"a" - tryb append (do dodawania czegoś do pliku). W tym trybie znacznik jest od razu na końcu pliku i nie nadpisuje zawartości.
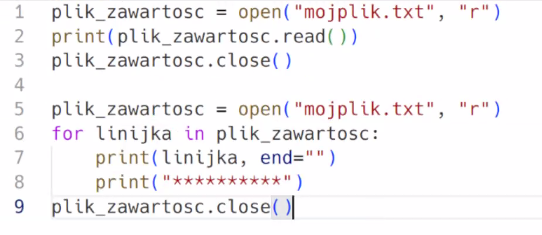

Dodajemy coś do pliku (tryby "w" i "a"):
# plik_zawartosc = open("mojplik.txt")
# # print(plik_zawartosc.read())
# for linijka in plik_zawartosc:
# print(linijka, end="")
# print("***")
# plik_zawartosc.close()
# plik_zawartosc = open("mojplik.txt", "w")
# plik_zawartosc.write("Nowa zawartosc.")
plik_zawartosc = open("mojplik.txt", "a")
plik_zawartosc.write("\nNowa zawartosc")
plik_zawartosc.close()Ma problem z polskimi znakami i zapisuje je jako romby z pytaniami. Żeby nie mieć tego problemu trzeba podawać, w jakiej tabeli kodujemy (utf-8).
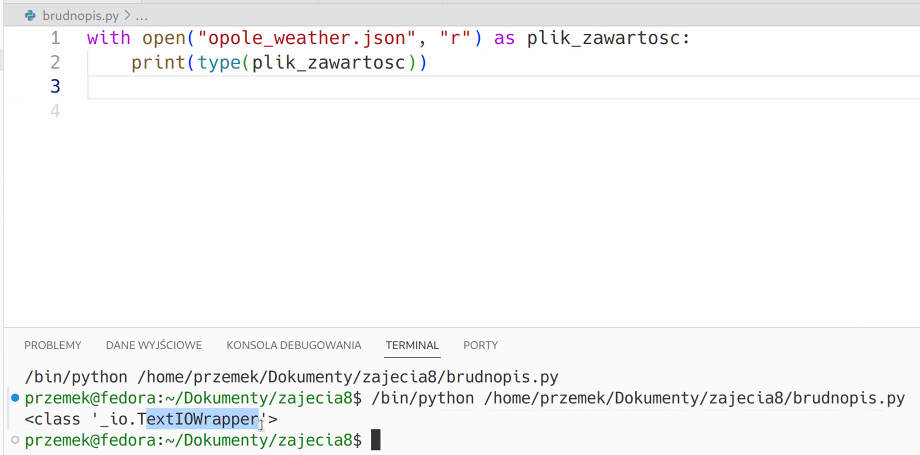
Jest sensowniejsza i lepsza metoda otwierania plików, kiedy nie trzeba pamiętać o ich zamykaniu .close()

kontekst manager with:
with open("mojplik.txt", "r") as plik_zawartosc:
print(plik_zawartosc.read()).csv jest plikiem tekstowym
Rozszerzenie nie określa, czy plik jest binarny, czy tekstowy. Najlepiej to sprawdzić otwierając w notatniku plik.

Format tekstowy zajmuje dużo miejsca, więcej niż binarny.
Binarny to 0 i 1, człowiek nie odczyta tego jako tekstu, ani tego nie otworzy domyślnie VS code.
.txt .csv .json .yaml .md(markdown), .py — formaty tekstowe
Binarne — zdjęciaa, fimy, 3d i td.
svg — tekstowy format do grafiki

csv — kolumny podzielone przecinkiem, wiersze — nowa linijka
Od formatu zależy głównie, jak są ustrukturyzowane dane w środku pliku tekstowego. Każdy ma swoje formatowanie.
.json — nawiasy do rozdzielenia linijek i td.

.json podobny do słownika w python, ale nie jest identyczny. True i False są inaczej kodowane w json niż w python.
.yaml — trochę inaczej niż w json. Trochę przyjaźniejszy dla odczytu przez ludzi.

Plik trzeba zamienić na słownik pythonowy (czy liste) i dopiero wtedy można na tych danych działać sensownie w python.
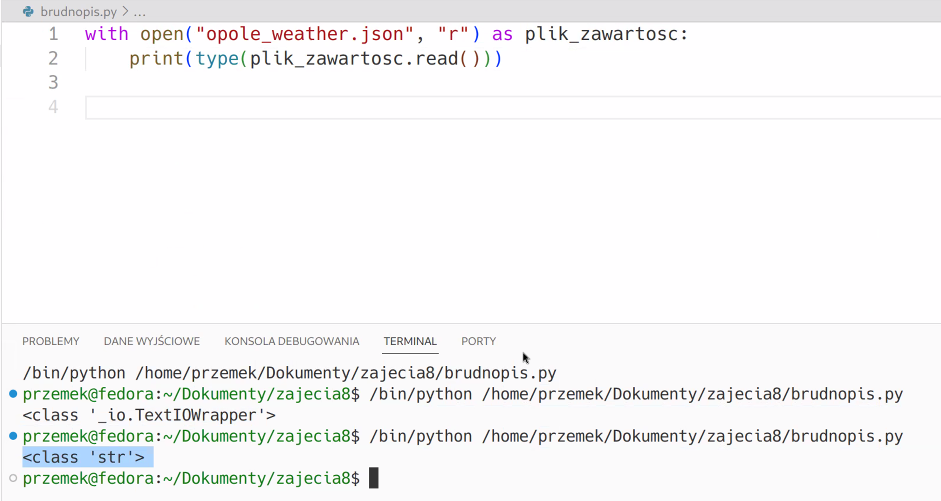
Python nie widzi w pliku swoich struktur danych, to tylko to jest string dla niego. Trzeba użyć biblioteki do odpowiedniego formatu, żeby przekształcić string w pythonową strukturę danych.
Używamy gotowych bibliotek dla serializacji i deserializacji danych. To jest zamiana pliku na pythonowe struktury i z powrotem.
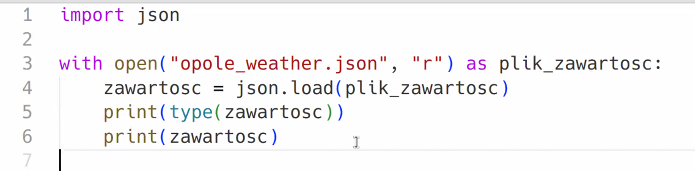
Większość aplikacji internetowych komunikuje się za pomocą json.
import json
with open("sw_starships.json", "r") as plik_zawartosc:
zawartosc = json.load(plik_zawartosc)
print(type(zawartosc))
print(zawartosc)Plugin, żeby nie wpisywać nazwy pliku, żeby się nie pomylić istnieje, ale trzeba zrobić własny research.

json.dump(1 pozycja - co wrzucam, 2 - dokąd)
dump — to metoda do wrzucenia danych do pliku. load — do odczytywania. dumps i loads to inne metody, nie mylić!
Jeżeli w folderze nie ma pliku z taką nazwą, to Python stworzy taki plik (przy trybie "w", w trybie "r" wyda error).
json i słownik nie są identyczne.
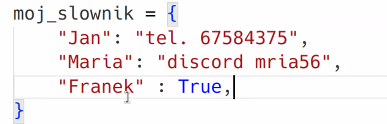

W json true jest z malej litery, i mimo że subtelna, ale ważna różnica to jest.
Parametr do formatowania danych w json: indent = int
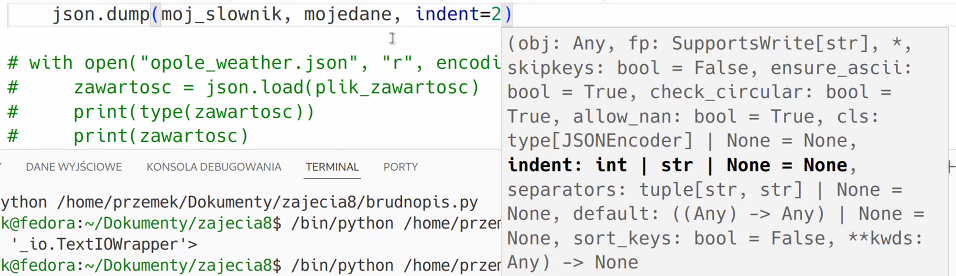
indent =2 — wcięcia , i każde wcięcie to 2 spacji, jeżeli podajemy znaczenie 2.
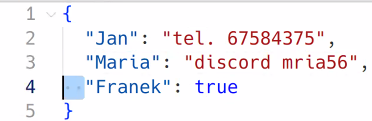
Przyjęło się ze w json wcięcia są 2-spacjowe. Nie muszą być.
ansible — narzędzie do zarządzania serwerami. yaml — przyjaźniejszy do konfiguracji.
.xml — przypomina html, przed json-em stworzony, ciut inny. Dobrze ustandaryzowany, urzędy go lubią.
.xlsx — binarny, word też. Oszukany plik binarny, bo excel to zzipowany folder z xml-ami. zmienic ręcznie rozszerzenie na zip i można zobaczyć co tam w środku
Pliki csv:

Jeśli nie musimy, nie korzystamy z csv, bo to są duże tabele raczej do analizy, bawienie się w inżyniera danych..... Jest niewygodna raczej. Biblioteka pandas jest lepsza do pracy z csv, wczytują pliki csv. od razu zamieniają csv na ramkę danych.
import csv
with open("currency.csv", encoding="utf8") as mojplik:
tabelka = csv.reader(mojplik)
# print(tabelka)
for wiersz in tabelka:
print(wiersz)ctrl + strzalka!!!! ctrl+enter - nowa linijka i inne skróty klawiszowe 😄

Ważne do zapisywania do json - ensure_ascii = False. Wtedy na pewno zapiszę z wykorzystaniem podanej tabeli kodowania znaków.
pandas — biblioteka do analityki danych i inżynierii danych

nympy - biblioteka do danych też.

as pd tak się przyjęło
pandas operuje na data frame (df)
pandas wyświetla tylko początek i koniec tabelki w terminalu, bo drukowanie to bez sensu

Tak można wydrukować całą tabelę, ale to rzadko jest potrzebne:
import pandas as pd
currency_df = pd.read_csv("currency.csv")
print(currency_df)
Na ostatnich zajęciach dostaniemy rekomendacje książek.


folder wyżej ".."
Jedna kropka "." to ten folder, w którym jesteśmy
To wszystko to — Obsługa systemu plików. Poczytaj więcej.
Sprawdzić, czy plik istnieje
Biblioteka os:

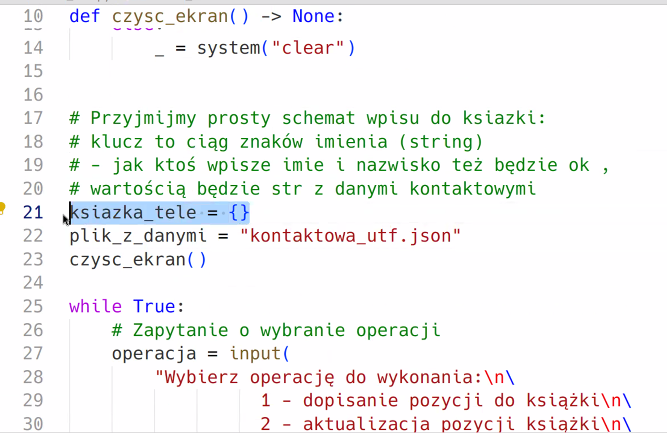
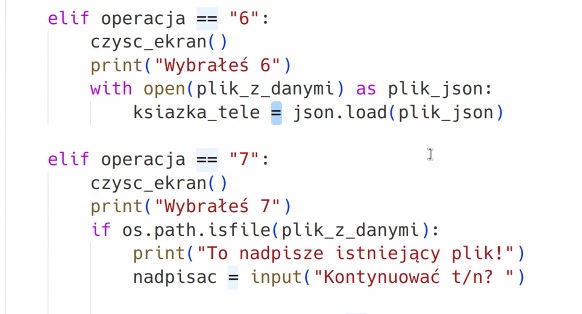
Tu robimy dodatkowe funkcje do książki telefonicznej z zapisywaniem do pliku json i odczytywaniem pliku json z kontaktami:
elif operacja == "7":
with open("ksiazka.json", "r", encoding="utf8") as moja_ksiazka:
do_wydruku = json.load(moja_ksiazka)
print(do_wydruku)
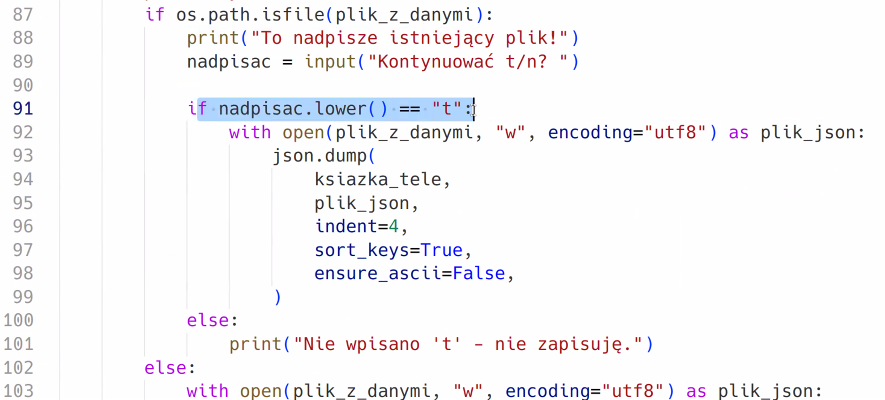
elif operacja == "8":
if os.path.exists("ksiazka.json"):
print("Uważaj, twoj plik z ksiazka zostanie nadpisany!!!")
with open("ksiazka.json", "w", encoding="utf8") as moja_ksiazka:
json.dump(ksiazka_tele, moja_ksiazka, indent = 2, ensure_ascii = False)
print("Twoja książka zapisana") Tak wygląda rozwiązanie Przemka:

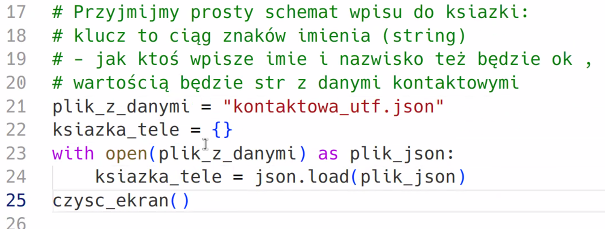


Dwa ukośniki. Ukośnik — znak ucieczki, żeby pominąć przejście do nowej linijki w samym kodzie, podawany jest drugi (niebieski) ukośnik.
Zrobić w weekend: zapisywanie do json do kwestionariusza, czyli wczytywanie pytań i odpowiedzi z pliku do kwestionariusza na początku
Zrobić osobny kod do podawania pytań i odpowiedzi do pliku json ankietowego, żeby poszerzyć kwestionariusz



