Struktury danych - zajęcia 4

- Listy (list) ~półka na książki
- są modyfikowalne (mutable) m2.append(8) doda do listy m2 element 8
- przemieszczamy się po elementach na liście
- raczej nie sięgamy po elementy, które znajdują się w środku listy, chyba że znamy dokładny indeks owego elementu
- deklaruje się je poprzez nawiasy kwadratowe []
moje_ksiazki = ["Blade Runner", "Hobbit", "Unicorn Project"]
- Krotki (tuple) ~kategorie w menu
- są niemodyfikowalne (immutable) k1.append("pies") wywoła error
- mają stałą długość, możemy z nich wyciągać elementy z samego środka
- deklaruje się poprzez nawiasy okrągłe ()
menu = ("przystawki", "zupy", "dania główne", "desery")Indeksy
Każdy element w strukturze danych ma swój numer, swoje miejsce - indeks. Zaczynamy liczyć od 0, nie od 1 Ujemne indeksy możemy wykorzystać do wyciągania elementów od tyłu, ostatni element struktury będzie miał indeks -1
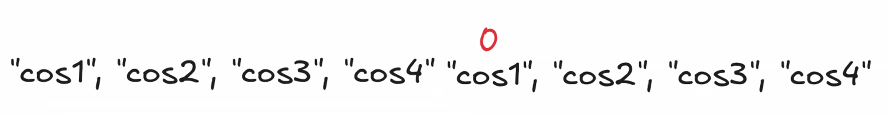
moja lista = ["cos1", "cos2", "cos3", "cos4"]
print(moja_lista[1])
> cos2
print(moja_lista[3])
> cos4
print(moja_lista[-1])
> cos4
print(moja_lista[-4])
> cos1Możemy także wyciągać kilka elementów na raz. Trzeba pamiętać, że w tym poleceniu liczenie zatrzyma się przed wskazanym elementem, nie wliczając go do wyświetlonego wyniku (polecenie print(moja_lista[1:3]) wyświetli elementy z listy [moja_lista] o indeksach 1 i 2, bez 3) Możemy także wywoływać przedziały niezamknięte z jednej ze stron [2:]/[:2]
moja lista = ["cos1", "cos2", "cos3", "cos4"]
print(moja_lista[1:3])
> ['cos2', 'cos3']
print(moja_lista[2:]
> ['cos3', 'cos4']
print(moja_lista[:2]
> ['cos1', 'cos2']Table unpacking
mlist = [1,2,3]
a,b,c = mlist
a
1Metody
To specjalne funkcje przypisane do danego obiektu. Mają strukturę:
zmienna.metoda()
.count(): zlicza ilość wystąpień danego parametru [listy/krotki]
.index(): podaje pierwszy indeks pod którym jest przekazana wartość [listy/krotki]
.append(): dodaje element [listy]
.pop(): usuń element o danym indeksie/ostatni element [listy]
.sort(): sortuje elementy [listy]
.copy(): zwraca kopie obiektu [listy]
.split(): dzieli stringa na części i zwraca jako lista, domyślnym rozdzielnikiem jest spacja
Papier, kamień, nożyce
import random
gra = ["papier", "kamień", "nożyce"]
y = random.choice(gra)
x = int(input("Wybierz papier = 0, kamień = 1 albo nożyce = 2: "))
print(f"Komputer wybrał: {y}")
yy = gra.index(y)
if (x==0 and yy==0) or (x==1 and yy==1) or (x==2 and yy==2):
print("Remis")
elif (x==0 and yy==1) or (x==1 and yy==2) or (x==2 and yy==0):
print("Wygrałeś! <3")
else:
print("Komputer wygrał :C")
Inne struktury danych:
- Słowniki (dictionary)
- umożliwiają szybkie odnalezienie jakiejś zawartości dzięki przypisanemu kluczowi
- klucz musi być unikalny i musi być obiektem niemodyfikowalnym (krotka musi być cała złożona z niemodyfikowalnych elementów)
- deklaruje się poprzez nawiasy-klamerki {}
- powinniśmy trzymać się określonych zasad przy wybieraniu nazw kluczy
moj_slownik = {"klucz1":"wartosc1", "klucz2":"wartosc2"}Metody dla słowników
.keys(): zwraca listę kluczy słownika
.values(): zwraca listę wartości słownika
.pop(): usuwa element o podanym kluczu
*menu/pop("soki") -> usunie całą listę soki ze słownika menu
*menu["soki"].pop(0) -> usunie element o indeksie 0 z listy soki ze słownika menu
.items(): zwraca listę krotek dla każdej pary klucz: wartość
.get(): zwraca wartość dla danego klucza
.clear(): czyści cały słownik
- Zbiory (set)
- nie mają indeksów, ani kluczy, przez co nie możemy odwołać się do konkretnego elementu
- nie mogą zawierać żadnych powtórzeń
- deklarujemy je jak słowniki, nawiasami-klamerkami {}
- możemy je wykorzystać np. aby pozbyć się duplikatów z listy, zamieniając listę na zbiór
Zadanie domowe:




